人工智能是计算机出现之后发明的,用机器来模仿人类学习和其他智能的技术。
是否会出现超越人类的机器生命是颇具争议的话题,混沌的数字世界需要我们携手同行。

相比数据,机器智能的发展历史远没有那么悠久。虽然人类历史上有过关于智能生命的诸多神话和幻想,比如古希腊火神赫菲斯托斯用黄金锻造的机器人少女,文艺复兴时期的炼金术士通过注入意识制作的人工生命何蒙库鲁兹,以及19世纪幻想小说中会思考的机器人等等。但真正进入科学家严肃研究视野的机器智能始于20世纪40年代基于抽象数学推理的可编程数字计算机的发明。
由于分析和理解常常容易产生误差,人类发明了数学这一相对精确的工具。在描述了一些基础问题后,历史上许多伟大的数学和哲学学者开始试图将一切人类思考过程都简化为数学表达。霍布斯就在其著作《利维坦》中谈到:“推理就是计算“,罗素和其老师怀特海共同撰写的《数学原理》则想要证明整个纯粹数学是从逻辑的前提推导出来的,并尝试只使用逻辑概念定义数学概念。
然而罗素等人的理论在很多情况下只能是设想,因为那时的我们还远远没有掌握海量的数据资源,也就无法真正将数理逻辑全部付诸现实领域。计算机的发明深刻地改变了这一状况,通过快速迭代的计算能力,它在短短几十年间不断地突破着人类对于数据边界的想象。著名的邱奇-图灵论题就曾指出:一台仅能处理0和1这样简单二元符号的机器(计算机)能够模拟任意数学推理过程——既然计算机有一天可能“推理万物”,这就大大激发了人类探讨机器思考的兴趣。
— 人工智能 深度学习 神经网络 —
后来我们将这种计算机能够模仿人类思考的技术称之为人工智能(Artificial Intelligence,简称AI),该词源自1956年的达特茅斯会议。在这次会议中,一群计算机和信息科学专家花了两个月的时间讨论“用机器来模仿人类学习以及其他方面的智能”的问题。虽然最后大家并没有达成普遍的共识,但是却为会议讨论的内容起了一个名字:人工智能。这标志着人类更为清晰地认识到计算机可能发挥的巨大价值,并希望借此发明一套能够帮助我们解决数理逻辑的应用和提升人类自身智慧的方法,1956年也被普遍认为是人工智能的元年。
在这之后的50至60年代中期,AI迎来了第一波高潮。这个阶段的AI在多个领域都取得了突破性的成绩。这其中包括独立证明罗素《数学原理》中的若干条定理,以及击败跳棋的美国州冠军等,我们惊呼不久就会产生超越人类智慧的计算机器。但很快,研究者发现自己对未来的估计过于乐观,由于计算机性能的瓶颈、计算复杂性指数级增长以及数据量缺失等原因,在完成一些初级问题的回答之后,AI在语音识别、机器翻译等领域迟迟不能突破,行业很快陷入低谷。
1980年代,一类名为“专家系统“的AI开始为全世界的公司所采纳,它的优势在于能够依据一组从专门知识中推演出的逻辑规则回答解决某一特定领域的问题。由于设计简单、容易编程且能够规避不少常识错误,专家系统在医学诊断、气象预测、工程物理等多个领域发挥了作用。
如果说最初的AI是人类在刚刚获得新工具的时候自信满满地全面进击的话,专家系统则是我们暂时与远大情怀作别,退回到一步步去解决具体问题的实践之中。但这一次的“脚踏实地”也没能持续多长,在经历了几次耀眼的亮相之后,专家系统很快就由于维护费用高昂,且实用性仅针对某些特定场景逐渐式微。进入到90年代初,不仅仅是专家系统,整个AI行业都因无法找到合适的发展路径而彻底停滞不前。
这个时候的很多人已经对所谓智能不再抱希望,整个技术界都不看好AI的未来,许多顶尖的计算机科学家也纷纷离开了这个行业。到了90年代中期,很多研究团队甚至已经拿不到任何的资助。但即使面临这样的窘境,以后来被称为“深度学习之父”的辛顿教授为代表的一群资深研究人员仍旧没有放弃。在获得了加拿大高级研究所的赞助之后,辛顿团队迁往了多伦多,与他同期的理查德·萨顿和约书亚·本西奥同样也在加拿大政府的支持下,以坚韧的精神继续着自己的研究。
我们常常说的对于一项新事物,人类很容易在短期内高估,而在长期低估其价值——这句话用在AI身上再合适不过了。上帝为人类打开了一扇门,只不过他担心挤进去的人太多,而且不够虔诚,所以总是会颇费心机的为我们设置重重障碍。很多时候,疑惑的产生不过是我们没有投入足够的思考和耐心,找出混沌中左右事情发展的关键矛盾而已。好在总有一些像辛顿这样的杰出人物,能够不为外界一时的看法所动,始终专注地坚持着自己的理想,并静静等待触发它转变的临界点。
对于AI来说,这个临界点就是数据。没错,就是一开始我们早就习以为常的数据。我们在之前大数据的文章中也已经提到,数据量在达到一定的规模之后,就可以发挥与以往完全不同的巨大影响力。就在AI研究者们人生中最为灰暗的时刻,对行业未来走向起到至关重要作用的互联网技术逐渐在商业领域走红。伴随着互联网的兴起,数据维度和数量急速增加,我们在前面文章中谈到的始于70年代的数据统计驱动的方法开始发挥价值。通过引入这一方法,AI开始进入又一轮发展高潮。
尤其是2006年以来,由辛顿等人主导的深度学习、人工神经网络的研究方法开始大放异彩,将AI从实验室和小规模场景真正推向了应用化、商业化的前台。今天我们一谈到AI,很多问题都会和它们相关,比如人工神经网络听上去很神秘,意思是AI在模仿人脑的神经系统吗?深度学习是说计算机可以像人类一样学习和掌握复杂深入的知识?在这个基础上,未来会不会有能够替代人类的智能出现?诸如此类等等。

对于上面每个问题的回答都不简单。AI本身就包含各种复杂的数学和计算模型,加上媒体五花八门的报道,常常会把很多非专业人士弄得一头雾水。我们大可不用理会这些晦涩的概念,仅仅稍微了解一下AI的发展轨迹,就可以获知以上问题的基本答案。
AI主流技术的发展经历过三个阶段。第一个阶段大致对应我们前面所说的达特茅斯会议之后的早期通用人工智能时期。我们认为只要机器被赋予逻辑推理能力就可以实现智能,因而倾向于利用AI解决所有的问题。第二个阶段开始,不同的学术派别、研究方法此起彼伏,我们上面谈到的专家系统大多采用的就是这其中一支叫做“符号学派”的方法。与第一阶段不同,这个时候最有影响力的观点是需要将人类知识总结起来灌输给AI。
第三个阶段一直持续到今天,在拥有了更多数据之后,这个阶段的主要方法是将计算机需要学习的数据丢进一个复杂的、包含多个层级的数据处理网络,也就是我们经常听说的人工神经网络(其实只是借用了生物学名词做了形象的比喻而已,和人脑没有半点关系),然后不断调整结果数据直至得到满意的目标模型。这个分析过程非常像人类学习新知识,于是科学界给它起了一个名字叫做“深度学习“。AlphaGo战胜李世石主要采用的就是这种方法,通过在单个围棋领域不断地对机器进行数据“训练”,AlphaGo在这个代表人类最高智慧的游戏上所具备的“聪明”程度已经超过了我们。
— 算法算力 AlphoGo 数字编码 —
关于未来会不会有替代人类智能的机器出现,这是一个老生常谈,且一直存在争议的话题。但至少目前可以比较肯定的是,我们现在还处在弱人工智能的时代,只能依赖AI解决一些局部的问题。虽然AI已经在围棋中获胜,但这并不代表它能够在各个方面都超过人类——从某种角度来说,那只不过是通过给机器“喂”数据得到的暴力破解结果而已。
判断AI是否超过人类的更为核心的标准在于其是否能够具备跨领域推理、抽象和尝试的能力。考虑到目前的AI在这些方面还相当稚嫩——比如懂得下围棋的程序并不能欣赏棋局中的博弈之美,也不能将之抽象出来用于商业决策,人类距离开发真正能够达到甚至超越自身智慧的物种还有相当长的路要走。
但无论如何,我们已经切身体会到AI带给我们的便利。借助对大数据的使用,世界被亚马逊、腾讯们的算法围绕着。它们精心计算着人类社会发生的一点一滴,并且小心翼翼地进入到我们的生活。AI会根据你过往的消费记录,智能的计算出你的消费倾向,并据此推送旅游折扣券或者促销信息给到你,你甚至会惊奇地发现它能够预测到你下个月国外旅行的计划;AI还可以帮助我们翻译论文、查找资料,以及在不久的将来为所有人驾驶汽车。人类开始有能力把自己从日常琐事中解放出来,从事一些更加高级的工作,并拥有更多时间去娱乐和享受生活。
在这个智能的世界,一切将会变得更加高效。AI会帮我们寻找复杂问题的解决方案,从而省去许多无谓的奔波;AI将会朝着越来越接近人类智慧的方向发展,直到有一天带给我们目前无法想象的繁荣……说到这里,我们似乎找到了之前文章中提出的问题的答案,脑海中再一次涌现出完美世界的图景。我们知道AI是在大数据基础上建构的一整套算法模型,既然如此,我们是不是可以把这个理想的世界简单表述为下面的公式:
理想模型=(万物数据化+相对精确+相关性)+算法
似乎还缺点什么?对了,我们还需要很多很多这样的机器,开足马力去计算所有复杂的数学方程,也就是被全部数据化了的世界,然后只需给到人类一个简洁优美的答案。按照严谨的计算机语言,能够支撑这个世界高速运转的机器的能力被统称为“算力”。我们再将前三项合并为“理想数据模型“,这样公式就可以被写作:
理想模型=理想数据模型+算法+算力
因为算法和算力作用的发挥非常依赖大数据的搜集和发展,因而我们暂时没有在公式中给它们加上任何限定的词汇。在算法方面,目前的AI实际上是以大数据的相对精确、相关性为底层,比如AlphaGo和它之后的改进版本主要都是通过不断丰富数据实现迭代升级的,虽然模型本身也会调校,但相比早先的算法改进并不大。而且AlphaGO在下棋的时候,算法也不会告诉它为什么要下这一步,只是程序的计算结果说明这样走更合理而已。
从算力角度,AI也在不断地提升,以匹配持续增加的数据计算量。AlphaGo的计算能力已经是1997年战胜当时国际象棋世界冠军的IBM计算机“深蓝”的3万倍。而即使是二十多年前的深蓝,每秒钟的计算就已经达到两亿步,并且输入了一百多年来优秀棋手的两百多万盘对局。

正如有一天随着大数据“大“到一定程度之后,相对精确和相关性可能会显得不再必要,我们现在对于算法和算力的理解也可能随着技术的进步而产生改变。在未来的某个时候,人类可能会掌握更精确的算法模型,即使在小数据的场景中也能够解决问题;在这种情况下,算力也就不会无限地增长下去,而是在达到新的临界点后开始下降。这样计算资源是否就能被极大地节省下来?我们又会将这些剩余的资源投入什么新的领域呢?是用于人类大脑和基因的改造?还是去探索无尽的宇宙?
我们暂时还无法完整地回答这些问题, 但是我们可以从智能的发展历史中找到一些脉络。 以语义理解为例, 我们的故事仍旧从熟悉的混沌-矛盾-演化模型开始。 我们的祖先在五千多年前发明了最早的文字, 而后又经过漫长的历史演变, 逐渐形成了较为完善的语言表达和语法的规则。
人类主要就是通过学习语言、文字来了解新知识的。后来我们知道数字从中分离出来,并且在之后的几千年与文字越走越远。但二者之间并不是毫无联系的,由于数字具有一些文字不具备的属性,比如更有利于确保信息传递的无误,早在公元前4世纪,我们就已经开始尝试将一些语言和文字转化为数字进行表达。例如当时犹太人为了避免圣经在抄写中的错误,会将每一个希伯来字母对应成一个数字,这样每行文字加起来便得到一个特定的数字,以此作为这一行的校验码。
进入到20世纪,人类又将大量文字转换成数字编码写入计算机,并通过智能的模型对其进行理解和推演。AI最基本的应用场景就是让机器模仿人类去理解这些文字和它背后所表达的语义,也就是我们常常听到的自然语言理解。
语义理解的历史由来已久,中国汉代许慎的著作《说文解字》,就是对汉字字形、来源及词意的解析;北魏郦道元编写的《水经注》,也是对先人地理古籍《水经》进行框架上的陈述和表意上的解释扩展。
除了对文字和语句进行解析之外,广义的自然语言理解还包括机器翻译,以及语音识别和知识理解等等。制作于公元前196年的古埃及罗塞塔石碑,用希腊、古埃及和当时的通俗体文字记载了国王托勒密五世登基的诏书,从1798年被人发现到1822年法国语言学家商博良对其破解翻译,前后花费了整整21年的时间。虽然在AI出现之后的翻译方法并没有比19世纪先进多少,但因为有了数据和计算模型,现在我们翻译石碑所需要花费的时间会远远少于当时。

时至今日,对于绝大多数不是特别复杂的论文、外文资料等,我们都能够借助机器进行理解和翻译。我们通过发明语音识别的程序,将国际会议演讲者的内容实时转换成多国语言;我们还可以借助余弦定理、贝叶斯网络等数学模型对文献资料进行分类,并从中抽取概念和分析主题。伴随着AI的发展,我们正在挣脱巴别塔的束缚,让思想和灵魂彼此碰撞。
— 自然语言理解 隐马尔可夫模型 同行 —
然而事情的发展并不是一开始就如此顺利,人类在通过计算机进行自然语言理解的道路上经历了不少矛盾和曲折。作为AI早期犯下的一系列错误的重要组成部分,最初我们在自然语言理解领域采用的方式也是把人类的经验传授给机器。这些知识主要来自于数世纪以来已经比较成熟的语言学的语法规则、语义分析等。但很快弊端就开始显现,首先是文法规则浩如烟海,即使用计算机覆盖哪怕20%-30%的真实语句,规则数量就已经多到语言学家来不及写的程度,并且随着覆盖度的增加,还要用新的文法规则解释当中产生前后矛盾的语句。
其次是文法在文章中体现出的上下文相关特性,用程序语言很难进行解析。计算机更加善于解码上下文无关的文法,举例来说,我们都知道中文博大精深,“方便”一词在不同的上下文语境中涵义大不相同。比如以下三个句子:
1. 我今天下午去你家找你,不知道你方便不方便——表示有机会、有时间;
2. 我晚餐有些吃多了,现在想去方便一下——表示排泄、大小便;
3. 我和张总是老同学了,希望在这次合作上贵公司能够给予方便——提供便利、帮助。
理解这些意思需要较好的生活常识,而基于规则方法组织起来的AI往往对此处理效果不佳,这也就是我们之前谈到的现在的AI还难以和人类拥有同等智慧的情形。
但人类会就此变得束手无策了吗?答案是否定的。我们发现有些事情并不是没有合适的解决方案,需要的仅仅是一些看问题的角度转换而已。既然问题出现在人类在语言学上积累的规则和经验难以有效转移,那么不妨让我们换一个角度。1970年以后,IBM华生实验室的贾里尼克教授就抛弃了我们一直以来对于语言规则的执着,转而采用统计学的方法处理AI遇到的问题,最早的尝试来自于当中的语音识别领域。
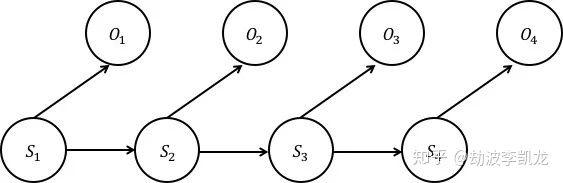
语音识别的本质就是机器将说话者表达的语音转化成文字的过程。比如我们现在对着Siri(苹果手机的语音识别程序)说话,IOS系统就可以将用户希望了解的天气、出行等各项信息推送出来。在这里说话者的一系列语音首先被手机记录下来,我们用o1,o2,o3…(观测信号)来表示。接收到这些信号后,AI将推测出这些信息的本来样子是s1,s2,s3…(信号源信息)。接下来AI会根据推测结果向系统发出相应的调取指令,最后, 收到这些指令的系统将会回复给用户“今日天气晴朗”,“建议改换路线躲避拥堵”等信息。
在应用统计方法之前,计算机要识别出复杂的人类语音需要学习大量的语法规则,而转变的核心就是将这个学习过程简化为概率统计模型。上面的例子中,问题变成了从所有的源信息中找到最可能产生出观测信号的那一个信息。也就是在已知o1,o2,o3…的情况下,求令条件概率:
P(s1,s2,s3,...|o1,o2,o3,...)达到最大值的那个信息串s1,s2,s3…,即
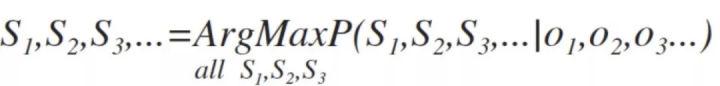
这个公式比较复杂,但可以用隐马尔可夫模型来估计,语音识别也成为隐马尔可夫模型最早成功应用的场景。隐马尔可夫模型是指这样一种情况,其输入状态是不直接可见的,但输出依赖于该状态下,是可见的,每个状态通过可能的输出记号有了可能的概率分布。
对应到上述案例中,也就是运用该模型,在给定已知参数的条件下,用概率的方法求出公式中不可见(隐含)的信号源信息。贾里尼克领导的实验室在当时提出用隐含马尔可夫模型来识别语音,使得错误率相比之前降低了2/3。接下来,这一模型还被陆续地用于基因测序、股票预测和投资等多个行业。对此吴军老师的《数学之美》有非常详细地阐述,这里我们不做具体地展开。
除了语音识别,在机器翻译等其他自然语言理解的行业原理也类似。我们可以把翻译问题简单理解为AI很难像人类一样去推测文字背后所要表达的上下文逻辑,但是之所以能够给出较为正确的识别结果,在于它用概率的方法去判断代表不同意思的词汇出现在该语句中的概率。
比如“pen“在英语中的意思既可以译为“笔“,也可以是”围栏“,但是当句子中有“bag”(书包)一词的话,pen是笔的意思的概率将远远超过围栏,这时候机器给出的翻译结果就会是笔。通过这种方法的运用,计算机甚至完全不知道说话者要表达的是什么意思,仅仅通过进行概率计算就可以做出相对准确的识别。事实上,AlphaGO下棋的核心也是采用了概率统计模型,每一步决策的背后都是概率上赢面最大的考量。
然而通过统计模型解决自然语言理解问题的方法并没有在贾里尼克之后就被所有人接受,研究者们分裂成了规则学派和统计学派两大阵营。到了90年代初期,矛盾双方仍是唇枪舌剑不断,互不认同彼此的方法。之所以出现这种情况是因为规则学派的人认为统计方法只能处理浅层的自然语言理解的问题,深层次的研究则仍需借助规则经验的使用。直到2005年,随着数据的不断完备,Google基于统计方法开发的翻译系统全面超过基于规则建构的SysTran,自然语言的处理才完全演化成采用概率统计的方式,规则学派终于彻底退出历史舞台。
我们早就听说了不少关于坚持和放弃的故事,比如20世纪美国在技术上大幅领先的调频无线电技术花了整整半个世纪才彻底战胜调幅技术。我们也认为自己已经汲取了不少这方面的教训。什么时候放弃?何时又应该坚持?事情在时时处处考验着人类的智慧。然而问题在于身处其中的人们经常不愿意理性辩证地思考,却总是固执地觉得自己不会是错误的一方。
在图像和艺术绘画方面,逐步演进的AI也开始发挥威力。目前AI在人脸图像识别领域的精度已经达到了99.83%,这已经超过了人眼的平均精度99.15%。在艺术创作上,2016年微软的智能设备通过自主“学习”伦勃朗的作品绘画风格和主题“创作”了一张男子肖像画,参观者感觉它与挂在美术馆的伦勃朗真迹相比一点也不突兀。
近些年我们讨论AI,并不会过多涉及人脑和意识模拟的话题,而是将重点集中在解决实际落地的问题之上。但这种AI能够代表所谓的智能吗?著名学者侯世达就在近期接受的采访中表示,目前的AI不过是对数据的妥协下制造出的很厉害的解题程序而已,根本谈不上真正的智能。在其于上世纪70年代末撰写的传世名作《GEB》(《哥德尔、艾舍尔、巴赫书:集异璧之大成》)一书中,就曾主张人类可以通过认知的循环升级,最终创造出超越自身的智慧和意识,让机器能够产生机器本身。

如果按照这种说法,或许我们现在发明的所有AI工具,从更长的人类历史来看,远远还不能被称为智能?未来的智能需要具备意识和情感吗?它是否需要拥有和人类一样的同理心?我们理想中完美的智能世界,是仅仅包含了物质的存在,还是也应该具有主观的精神和意志?
回到我们最初的理想模型,或许真到了智能可以搞定一切问题的时候,我们可能不愿意全部交给它处理,因为担心聪明的计算机侵犯我们的安全和隐私?我们需要适应AI带给我们的一系列变化,比如机器将会替代大量人类的工作,这种情况下我们应该以何谋生?智能的机器会变得越来越强大,为了规范它们和人类的共处模式,是否又需要建立新的法律和社会秩序?
在AI快速发展的今天,人类已然拥有了无比丰富的知识,全世界的经济发展为何仍不时陷入困境?除了自然因素之外,为什么我们居住的土地上仍然存在大量的饥荒和瘟疫?AI帮我们克服了许多过去无法克服的难题,为什么人类依然经常生活在冷漠和猜忌之中?我们的生产力在大数据和智能的助推下获得了长足的进步,但为什么彼此的信任和协作还是难以大范围达成?
这样看来,我们的问题可能并不是什么数据或者智能,如果仅仅依靠它们也根本无法建立人类心目中的完美世界。一定存在着某个关键的方法,只是我们暂时还没有发现而已。即便我们访遍了地球上每个数据的角落,也用AI翻阅了无数的经典,却久久无法找到问题的答案。在科技为我们不断创造繁荣的同时,无论是西方还是东方,正在被越来越多的焦虑和无措的情绪所笼罩。站在无边的旷野上,人类四处张望,却总是无法找到一个温暖的拥抱;即使身处繁华和喧嚣之中,有美酒和音乐相伴,我们的心却还是时不时感到落寞和孤单。
终于在2009年,一个名叫中本聪的家伙在他发明的比特币上给了我们最初的提示,后来我们又从中提炼出区块链这项新的技术,并已经开始着手将它应用于解决各项棘手的问题。区块链将为我们提供大规模信任的基础,消除猜忌和疑虑,降低彼此间沟通的成本。借助这一技术,大数据、AI和量子计算们可以发挥更大的价值,从而帮助我们穿越低潮和迷雾吗?在它的帮助下,人类或许就可以携起手来,勇敢地走进混沌的数字世界,然后一起迈向更完美的远方?无论如何,对于我们来说,这是又一次巨大的希望。
数字无界,愿相伴同行!

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}